Data Splitter Tutorial
The general setup sequence for Data Splitter solutions is as follows :
- define input and output streams
- define sets, patterns, variables and counters
- define nodes and links (the PGraph)
- define the actions to perform
- run
This tutorial contains examples of the following :
See the Data Splitter dialogs topic for more information.
The samples referred to in this tutorial are distributed with the program.
Example 1: Determine the line count of a group of text files (sample: File-Count-Lines.dss)

In other words, count the "newline" characters in a group of files. Newline characters may be carriage returns, line feeds, or carriage returns and line feeds. With Data Splitter you can define "newline" any way you want.
In this solution we're interested only in newlines. So, here's what to do :
- Start a new solution :
- select Solution | New to start a new solution
- if prompted "OK to lose changes" either:
press OK, or
press Cancel and select Solution | Save to save any work in progress
- Define the input files :
- select Input/Output | Input files to open the Input Files dialog
- list the file specifications to be scanned, for example: "*.txt"
- be sure to check the "Scan" box for each input file spec to be scanned
- press the OK button to close the Input Files dialog
- Define a single output file :
- select Input/Output | Output files to open the Output Files dialog
- in the Tag field enter "Results"
- move to the Output File Spec field and enter "LineCount.txt"
- press the OK button to close the Output Files dialog
- Define a variable, "newline", that is a sequence of two bytes, carriage return + line feed :
- select Definitions | Variables to open the Variables dialog
- enter "newline" in the Tag field
- move to the Type field, press F1 and select type "Byte"
- press the OK button to close the Select Type dialog
- in the Byte dialog enter decimal values 13 and 10 (carriage return + line feed) in the first two boxes
- press the OK button to close the Byte dialog
- press the OK button to close the Variables dialog
- Define a pattern, "NewLine", that consists of exactly one "newline" :
- select Definitions | Patterns to open the Patterns dialog
- enter "NewLine" in the Tag field
- press the Enter key or the Select button to open the "NewLine" pattern definition dialog
- press F1 in the Set field and select "newline"
- press the OK button to close the Select Set / Variable dialog
- enter "1" for both the Min and the Max
- press the OK button to close the "NewLine" pattern definition dialog
- press the OK button to close the Patterns dialog
- Define a counter, "NHitsTotal", whose initial value is zero :
- select Definitions | Counters to open the Counters dialog
- enter "NHitsTotal" in the Tag field in the first row
- enter "0" in the Initial Value field
- Define two more counters :
- move to the second row in the Counters dialog
- define "NHitsInFile" with initial value = zero
- move to the third row in the Counters dialog
- define "NFiles" with initial value = zero
- the dialog should now contain three counter definitions: "NHitsTotal", "NHitsInFile", and "NFiles", with initial value zero
- press the OK button to close the Counters dialog
- Define a node whose pattern is "NewLine" :
- double-click the left mouse button on the blank Data Splitter drawing surface to create a new node
- double-click on the node and select Properties from the drop-down menu
- in the Node Properties dialog, move to the Pattern field, press F1 and select "NewLine"
- press the OK button to close the Select Pattern / Node Group dialog
- press the OK button to close the Node Properties dialog
- you can resize the node by dragging its edges with the mouse
- Add two "Increment counter" actions to the "NewLine" node :
- double-click on the node and select Actions from the drop-down menu
- in the Action field, press F1, select "Increment counter" and press OK to open the Increment Counter dialog
- in the Counter field press F1 and select "NHitsInFile"
- press the OK button to close the Select Counters dialog
- leave the "By" field empty (it has a default value of 1, which is what we want)
- press the OK button to close the Increment Counter dialog
- move to the second row in the Actions dialog and add another "Increment counter" action, this time specifying the "NHitsTotal" counter
- the dialog should now contain two "Increment counter" actions, one for "NHitsInFile", the other for "NHitsTotal"
- press the OK button to close the Actions dialog
- resize the node with the mouse so that the actions are displayed at the bottom of the node graphic
At this point this Data Splitter solution opens files and counts the "NewLines" in them, but no output is produced yet.
- A line count total should be produced for each file
- A grand total should be produced at the end of the run
Also, the counters must be zeroed out and incremented at the appropriate times :
- All the counters should be cleared at the beginning of the run
- "NHitsInFile" should be zeroed before each file
- "NFiles" should be incremented for each file
Continuing the solution :
- Zero the counters at the beginning of the run :
- select Definitions | Actions: pre-run (#1) to open the Pre-run Actions dialog
- in the Action field, press F1 and select "Set counter" to open the Set Counter dialog
- in the Counter field press F1 and select "NFiles"
- press the OK button to close the Select Counters dialog
- move to the Value field and enter zero
- press the OK button to close the Set Counter dialog
- move to the second row in the Pre-run Actions dialog, press F1 in the Action field and use Set Counter to set "NHitsInFile" to zero
- move to the third row in the Pre-run Actions dialog and use Set Counter to set "NHitsTotal" to zero
- the Pre-run Actions dialog should now contain three "Set counter" actions, zeroing "NFiles", "NHitsInFile", and "NHitsTotal"
- press the OK button to close the Pre-run Actions dialog
- Set the per-file counters :
- select Definitions | Actions: pre-stream (#2) to open the Pre-stream Actions dialog
- in the Action field, press F1 and use Set Counter to set "NHitsInFile" to zero
- move to the second row in the Pre-stream Actions dialog, press F1 and use Increment Counter to add one to "NFiles"
- Note: incrementing "NFiles" could also be done in the Post-stream Actions
- the Pre-stream Actions dialog should now contain a "Set counter NHitsInFile 0" action and an "Increment counter NFiles" action
- press the OK button to close the Pre-stream Actions dialog
- Output the per-file results :
- select Definitions | Actions: post-stream (#3) to open the Post-stream Actions dialog
- in the Action field, press F1 and select "Send to" to open the Send To dialog
- in the Target field press F1 and select "Results"
- move to the Source field, press F1 and select "StreamName" - this sends the file name to the Results file
- press the OK button to close the Send To dialog
- move to the second row in the Post-stream Actions dialog, press F1 and select "Send to" to open the Send To dialog again
- enter "Results" in the Target again
- type at least one blank in the Prefix Text field
- move to the Source field, press F1 and select "NHitsInFile"
- press the OK button to close the Send To dialog
- move to the third row in the Post-stream Actions dialog, press F1 and use "Send to" to send "newline" (the Source) to "Results" (the Target)
- press the OK button to close the Send To dialog
- there should now be three "Send to" actions sending "StreamName", "NHitsInFile", and "newline" to "Results"
- press the OK button to close the Post-stream Actions dialog
- Output the final results -
configure three actions to send "NHitsTotal", a "newline", and "NFiles" to "Results" :
- select Definitions | Actions: post-run (#4) to open the Post-run Actions dialog
- in the Action field, press F1 and select "Send to" to open the Send To dialog
- set the Target to "Results", once again
- move to the Prefix Text field and enter a heading such as "Total lines: "
- note the trailing blank(s) on the Prefix Text
- move to the Source field, press F1 and select "NHitsTotal"
- press the OK button to close the Send To dialog
- move to the second row in the Post-run Actions dialog, press F1 in the Action field and use "Send to" to send a "newline" to "Results"
- move to the third row in the Post-run Actions dialog, press F1 in the Action field and use "Send to" to send "NFiles" to "Results"
- in the Prefix Text field and enter a heading such as "Files scanned: "
- press the OK button to close the Send To dialog
- there should now be three "Send to" actions sending "NHitsTotal", "newline", and "NFiles" to "Results"
- the "NHitsTotal" and "NFiles" actions should have meaningful text prefixes
- press the OK button to close the Post-run Actions dialog
- Save your work :
- select Solution | Save to open the Save As dialog
- enter a new file name
- press the Save button to close the Save As dialog
- Run the new solution :
- select Run | File input to scan the specified input files
- select View | Results to view the output file
- you should see a list of file names followed by their line count totals
- the bottom of the report should show totals for line count and number of files scanned
- selecting Run | Run will produce the same results, since no email or URL input is defined
Sample File-Count-Lines.dss extends this example by placing the results in an HTML table.
Example 2: Search for + replace text in ASCII files (sample: File-Search-Replace.dss)

In this solution we're interested in two types of data :
- the search text, i.e. the text to be replaced
- everything else
Two types of data, two nodes.
- Start a new solution :
- select Solution | New to start a new solution
- if prompted "OK to lose changes" either:
press OK, or
press Cancel and select Solution | Save to save any work in progress
- Define the input files :
- select Input/Output | Input files to open the Input Files dialog
- list the file specifications to be scanned, for example: "*.txt"
- be sure to check the "Scan" box for each input file spec to be scanned
- press the OK button to close the Input Files dialog
- Define a single target directory output file specification :
- select Input/Output | Output files to open the Output Files dialog
- in the Tag field enter "OutFile"
- move to the Output File Spec field and enter a wildcard specification, for example: "updated\*.*"
- Note: this should be an existing directory
- press the OK button to close the Output Files dialog
- Define an 8-bit set, "anything", containing values 0-255 (all possible values for a byte) :
- select Definitions | Sets (8-bit) to open the Sets (8-bit) dialog
- enter the word "anything" in the Tag field
- press the Enter key or the Select button to open the "anything" set definition dialog
- in the Start field enter "0"
- in the End field enter "255"
- press the OK button to close the "anything" set definition dialog
- press the OK button to close the Sets (8-bit) dialog
- Define a pattern, "*" (asterisk), that consists of 0-99999 "anything"s :
- select Definitions | Patterns to open the Patterns dialog
- enter "*" (asterisk) in the Tag field
- press the Enter key or the Select button to open the "*" pattern definition dialog
- press F1 in the Set field and select "anything"
- enter "0" for the Min
- enter "99999" for the Max
- press the OK button to close the "*" pattern definition dialog
- press the OK button to close the Patterns dialog
- Define a String Set, "new text", that contains the search text and replacement text entries :
- select Definitions | String sets to open the String Sets dialog
- enter "new text" in the Tag field
- press the Enter key or the Select button to open the "new text" String Set definition dialog
- enter the search text in the Text fields
- enter the replacement text in the Other Text fields
- make sure Enabled is checked for each Text/Other text pair to be sought / replaced
- press the OK button to close the "new text" String Set definition dialog
- press the OK button to close the String Sets dialog
For example :
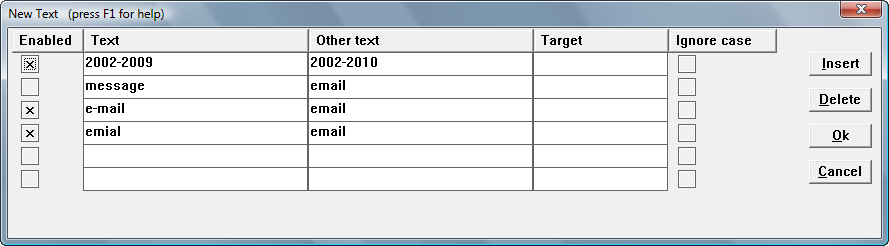
In this example "2002-2009" is replaced with "2002-2010", etc.
- Define the "catch all" node :
- double-click the left mouse button on the blank Data Splitter drawing surface to create a new node
- double-click on the new node and select Properties from the drop-down menu
- in the Node Properties dialog, move to the Pattern field, press F1 and select "*"
- press the OK button to close the Node Properties dialog
- Add a "Send to" action to the "*" node :
- double-click on the node and select Actions from the drop-down menu
- in the Action field, press F1 and select "Send to" to open the Send To dialog
- in the Target field press F1 and select "OutFile"
- leave the other fields (Prefix text & Source) empty
- press the OK button to close the Send To dialog
- the Actions dialog should now contain a single "Send to OutFile" action
- this action sends the node (input associated with the node) to OutFile
- press the OK button to close the Actions dialog
- Define the search text - replacement text node :
- double-click the left mouse button on the Data Splitter drawing surface to create a new node
- double-click on the new node and select Properties from the drop-down menu
- in the Node Properties dialog, move to the Pattern field, press F1 and select "new text"
- press the OK button to close the Node Properties dialog
- Add a "Send to" action to the "new text" node :
- double-click on the "new text" node and select Actions from the drop-down menu
- in the Action field, press F1 and select "Send to" to open the Send To dialog
- in the Target field press F1 and select "OutFile"
- move to the Source field, press F1 and select "new text"
- press the OK button to close the Send To dialog
- the Actions dialog should now contain a single "Send to OutFile [new text]" action
- press the OK button to close the Actions dialog
- resize both nodes with the mouse so the actions are visible
- Link the "*" node to the "new text" node :
- double-click on the "*" node and select Link to... from the drop-down menu
- move the mouse over the "new text" node and click on it
- there should now be a single link from the "*" node to the "new text" node
- Check that the "*" node is the "Start" node :
- if it isn't, double-click on the "*" node and select Start Node from the drop-down menu
- the "*" node should be marked "(Start)" in its upper left corner
- Save your work :
- select Solution | Save to open the Save As dialog
- enter a new file name
- press the Save button to close the Save As dialog
- Run it :
- select Run | File input to scan the specified input files
Use a file comparison utility such as "fc" or "windiff" to compare the output to the input. "OutFile" in this case has been defined with a wildcard file specification, so selecting View | OutFile will probably produce an error message such as "filename syntax is incorrect".
Example 3: Search for text in files (sample: File-Search.dss)
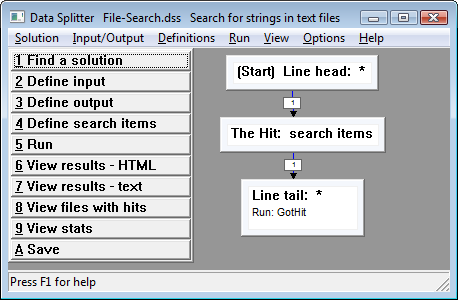
In this solution we're interested in the search text and the line in which it is contained :
- Start a new solution :
- select Solution | New to start a new solution
- if prompted "OK to lose changes" either:
press OK, or
press Cancel and select Solution | Save to save any work in progress
- Define the input files :
- select Input/Output | Input files to open the Input Files dialog
- list the file specifications to be scanned, for example: "*.txt"
- be sure to check the "Scan" box for each input file spec to be scanned
- press the OK button to close the Input Files dialog
- Define a single output file :
- select Input/Output | Output files to open the Output Files dialog
- in the Tag field enter "Results"
- move to the Output File Spec field and enter "TextSearchResults.txt"
- press the OK button to close the Output Files dialog
- Define an 8-bit set, "notnewline", containing everything except carriage return and line feed characters :
- select Definitions | Sets (8-bit) to open the Sets (8-bit) dialog
- enter "notnewline" in the Tag field
- press the Enter key or the Select button to open the "notnewline" set definition dialog
- in the first row enter "0" for Start, "9" for End
- in the second row enter "11" for Start, "12" for End
- in the third row enter "14" for Start, "255" for End
- in other words: 0..255 with 10 and 13 (carriage return + line feed) missing
- press the OK button to close the "notnewline" set definition dialog
- press the OK button to close the Sets (8-bit) dialog
- Define a pattern, "*", that consists of 0-99999 "notnewline"s :
- select Definitions | Patterns to open the Patterns dialog
- enter "*" (asterisk) in the Tag field
- press the Enter key or the Select button to open the "*" pattern definition dialog
- press F1 in the Set field and select "notnewline"
- enter "0" for the Min
- enter "99999" for the Max
- press the OK button to close the "*" pattern definition dialog
- press the OK button to close the Patterns dialog
- Define a String Set, "search items", that contains the text to be sought :
- select Definitions | String sets to open the String Sets dialog
- enter "search items" in the Tag field
- press the Enter key or the Select button to open the "search items" String Set definition dialog
- In the Text fields enter the search text items
- leave the other fields (Other text & Target) empty for this example
- make sure Enabled is checked for each text item to be sought
- press the OK button to close the "search items" String Set definition dialog
- press the OK button to close the String Sets dialog
- Define the beginning-of-line ("head") node :
- double-click the left mouse button on the blank Data Splitter drawing surface to create a new node
- double-click on the node and select Properties from the drop-down menu
- in the Node Properties dialog, enter "Line head" in the Tag field
- move to the Pattern field, press F1 and select "*"
- press the OK button to close the Node Properties dialog
- Define the search text ("hit") node :
- double-click the left mouse button on the Data Splitter drawing surface to create a new node
- double-click on the node and select Properties from the drop-down menu
- in the Node Properties dialog, enter "The Hit" in the Tag field
- move to the Pattern field, press F1 and select "search items"
- press the OK button to close the Node Properties dialog
- Define the end-of-line ("tail") node :
- double-click the left mouse button on the Data Splitter drawing surface to create a new node
- double-click on the node and select Properties from the drop-down menu
- in the Node Properties dialog, enter "Line tail" in the Tag field
- move to the Pattern field, press F1 and select "*"
- press the OK button to close the Node Properties dialog
- Link the "Line head" node to the "The Hit" node :
- double-click on the "Line head" node and select Link to... from the drop-down menu
- move the mouse over the "The Hit" node and click on it
- there should now be a single link from the "Line head" node to the "The Hit" node
- Link the "The Hit" node to the "Line tail" node :
- double-click on the "The Hit" node and select Link to... from the drop-down menu
- move the mouse over the "Line tail" node and click on it
- there should now be three nodes, and two links connecting "Line head" to "The Hit" to "Line tail"
- you can use the mouse to drag and resize / reposition the nodes
- Check that the "Line head" node is the "Start" node :
- if it isn't, double-click on the "Line head" node and select Start Node from the drop-down menu
- the "Line head" node should be marked "(Start)" in its upper left corner
The hit should be output when the "Line tail" node is recognized. At that point the beginning of the line, the hit, and the end of the line have been recognized. In other words, there's a line with a "hit" in it. So, output the name of the file containing the line and the line itself :
- Define a "NewLine" variable to use to separate lines in the output :
- select Definitions | Variables to open the Variables dialog
- enter "NewLine" in the Tag field
- move to the Type field, press F1 and select type "Byte"
- in the Byte dialog enter decimal values 13 and 10 (carriage return + line feed) in the first two boxes
- press the OK button to close the Byte dialog
- press the OK button to close the Variables dialog
- Define an action group that outputs the file name :
- select Definitions | Action groups to open the Action Groups dialog
- enter "FileNameToResults" in the Tag field
- press the Enter key or the Select button to open the "FileNameToResults" Action Group definition dialog
- in the Action field, press F1 and select "Send to" to open the Send To dialog
- in the Target field press F1 and select "Results"
- move to the Source field, press F1 and select "FullStreamName"
- press the OK button to close the Send To dialog
- move to the second row in the "FileNameToResults" Action Group definition dialog
- press F1 in the Action field and define an action that sends "NewLine" to "Results"
- there should now be two actions sending the stream name + a newline to "Results"
- press the OK button to close the "FileNameToResults" Action Group definition dialog
- press the OK button to close the Action Groups dialog
- Define an action group to execute when we've got a "hit" :
- select Definitions | Action Groups to open the Action Groups dialog
- enter "GotHit" in the Tag field in the second row (below "FileNameToResults")
- press the Enter key or the Select button to open the "GotHit" Action Group definition dialog
- in the Action field, press F1 and select "Execute action group" to open the Execute Action Group dialog
- in the Action Group field press F1 and select "FileNameToResults"
- check the "Execute once per input stream" box
- press the OK button to close the Execute Action Group dialog
- define four more actions to send "Line head", "The Hit", "Line tail" and a "NewLine" to "Results"
- press the OK button to close the "GotHit" Action Group definition dialog
- there should now be two action groups defined: "FileNameToResults" and "GotHit"
- press the OK button to close the Action Groups dialog
- Execute "GotHit" from the "Line tail" node :
- double-click on the "Line tail" node and select Actions from the drop-down menu
- in the Action field, press F1 and select "Execute action group" to open the Execute Action Group dialog
- in the Action Group field press F1 and select "GotHit"
- leave the "Execute once per input stream" box unchecked
- press the OK button to close the Execute Action Group dialog
- the Actions dialog should now contain a single "Execute action group GotHit 0" action
- press the OK button to close the Actions dialog
- Save your work :
- select Solution | Save to open the Save As dialog
- enter a new file name
- press the Save button to close the Save As dialog
- Run it :
- select Run | File input to scan the specified input files
- select View | Results to view the output file
- you should see file names and lines from those files containing the "search items" entries
When one of the search text items is encountered in a line that line will be sent to the "Results" file. The lines from each file will be preceded by the file name - setting "Execute once per input stream" when executing "FileNameToResults" outputs the file name just once per file.
The trick here is to get a line at a time by recognizing an "anything but newline" pattern. This effectively breaks the input into lines by restarting at the start node whenever a something not in that set, i.e. a newline (carriage return or line feed, decimal 13 or 10) is encountered.
In order for the "Line tail" node to be recognized the "Line head" and "The Hit" nodes must also have be recognized. In other words: because of the link order, Data Splitter can only get to "Line tail" via "Line head" and "The Hit". When "Line tail" is recognized the line containing the "The Hit" is simply the concatenation of the "Line head", "The Hit" and "Line tail" nodes.
Sample File-Search.dss extends this example by producing both text and HTML result files, plus a list of files with hits and a "stats" summary.